Parsing Proteins in the GenBank/GenPept Flat File Format with BioJava 1.8.1
This post describes parsing annotated protein sequences from the RefSeq database. I was unable to find any complete examples for parsing RefSeq protein sequences in .gpff.gz files with Java, so here is a quick and dirty one.
The Reference Sequence (RefSeq) collection aims to provide a comprehensive, integrated, non-redundant, well-annotated set of sequences, including genomic DNA, transcripts, and proteins. After downloading the latest release release from the FTP server, you end up with a lot of .gz files. An example of the filenames:
complete.1.1.genomic.fna.gz complete.1.bna.gz complete.1.genomic.gbff.gz complete.10.bna.gz complete.10.genomic.gbff.gz complete.100.protein.gpff.gz
The README tells us that the filenames describe the type of information (genomic, protein, dna, rna). This information is split up in many (numbered) files. We are interested in protein information in the GenPept/GenBank Flat File format. Every file with protein information in this format has a name of the form complete..
Oh, and the regular expression for these filenames is:
^complete.[0-9]+.protein.gpff.gz$
Writing a parser for these files is a lot of work, but luckily we can use the BioJava framework to do the heavy lifting. We use version 1.8.1, which can be downloaded here. This example requires three .jar files are included in your Java project: core-1.8.1.jar, bytecode-1.8.1.jar and sequencing-1.8.1.jar.
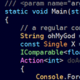
The code below opens a given .gz file, e.g. complete.1.protein.gpff.gz, and parses all protein entries:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
import java.io.BufferedReader; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStreamReader; import java.util.zip.GZIPInputStream; import org.biojava.bio.BioException; import org.biojava.bio.seq.ProteinTools; import org.biojava.bio.seq.io.ParseException; import org.biojava.bio.seq.io.SymbolTokenization; import org.biojava.bio.symbol.IllegalSymbolException; import org.biojavax.Namespace; import org.biojavax.RichObjectFactory; import org.biojavax.SimpleNamespace; import org.biojavax.bio.seq.RichSequence; import org.biojavax.bio.seq.io.GenbankFormat; import org.biojavax.bio.seq.io.SimpleRichSequenceBuilder; public void processFile(String fileLocation) { // Open the .gz file in a BufferedReader GZIPInputStream gzipInputStream = null; BufferedReader fileIn = null; Reader decoder = null; try { gzipInputStream = new GZIPInputStream(new FileInputStream(fileLocation)); decoder = new InputStreamReader(gzipInputStream, "UTF-8"); fileIn = new BufferedReader(decoder); } catch (IOException e) { log.error("Error opening file with GZIPInputStream: " + fileLocation, e); } // Initialize the GenBank/GenPept flat file format parser GenbankFormat gf = new GenbankFormat(); SimpleRichSequenceBuilder listener = new SimpleRichSequenceBuilder(); Namespace gbSpace = (Namespace) RichObjectFactory.getObject(SimpleNamespace.class, new Object[]{"refseqNS"} ); SymbolTokenization tokenization = null; try { // Tokenizer for the protein sequence. When parsing DNA you can use DNATools.getDNA().getTokenization("token") tokenization= ProteinTools.getAlphabet().getTokenization("token"); } catch (BioException e) { log.error("Error creating tokenization from ProteinTools().", e); } // Parse all protein entries in the file. boolean hasNext = true; while (hasNext) { try { hasNext = gf.readRichSequence(fileIn, tokenization, listener, gbSpace); RichSequence entry = listener.makeRichSequence(); // The protein sequence is now parsed and loaded into 'entry'. // Extract all the information you need here... } catch (IOException| BioException e) { log.error("Error reading RichSequence from RefSeq file.", e); } } } |
For more documentation on using the BioJava parsers check out this page on the BioJava wiki.